关于从业以来服务端日志若干历史问题的决议
服务端日志,既用于追踪程序状态,又用于数据分析,是非常重要的战略物资。
我们要将之一个不漏滴收集起来,科学有规划滴使用。
——无名吹水师
从一个早期的游戏项目说起。上线伊始我们将日志记录在文件中,简单有效。而随着日志增多,我们开始分类分日期存放。 后来由于增加了一些复杂的游戏玩法,服务端改用分布式架构分而治之。而日志也因此散落在不同机器上,好在规模不大,还能将就。
再后来,游戏开了上百个新服,日志散落的情况愈发严重。不光是查看程序状态日志需要登录不同机器, 连数据分析也开始乱套,聚合类统计压根无法进行,只能靠手工汇总来苟且,实在凄惨。
于是我意识到一个中心化的日志服务管理起来更容易,但直接迁移到开源方案上没啥底气(主要是害怕丢日志)。 只好先折中,使用 rsync 将所有机器上的日志同步到一台高配机上集中处理(32核机干这种脏活………)。 简单易用,成果直观。但弊端也有,最先造成麻烦的是实时性。网上倒有 inotify 配合 rsync 的解决方案,见例子:
while true; do
inotifywait -r -e modify,attrib,close_write,move,create,delete /path/to/src_dir/
rsync -avz /path/to/src_dir/ logporter@gameserver01:/path/to/dest_dir/
done
虽然可行,但有很大瑕疵,主要在于:
- CPU算力浪费。rsync 每次启动会重读日志文件内容分块算 hash ,传输前还会做压缩。频繁启动它会导致 CPU 负载过高,尽管可以按日期分目录,但也只是五十步笑百步。
- 逻辑丑陋。从 rsync 进程运行结束后到下一轮 inotifywait 进程启动前总有点时间间隔,这中间发生的文件变化可能会漏掉,除非日志文件一直在持续写。也许不值得计较,但总归是个逻辑问题……
综上,rsync 方案并没有多好,付出了很大代价(硬件资源,心理压力,以及运维工作量)才换来分布式环境下日志中心化的局面。
无论如何,日志中心化的问题暂且按下,但其它问题却显得尖锐起来。比如我们检索程序日志要反复 grep -P "$regex" 一堆文件,正则动不动就复杂到需要抄小本本。 而数据分析方面,使用 python 硬编码实现的统计代码可维护性很差,远不如 SQL 简洁。眼看着要变成屎山,我于是写了个程序将日志增量导入到 OLAP 系统以支持 SQL。 至此,这个歪歪斜斜的日志收集“系统”进化到关键点了,还有以下几点缺陷需要解决:
- 过程复杂。日志经由业务进程 => 磁盘 => rsync => 日志中心(磁盘) => 我的程序 => OLAP 系统。
- 投递实时性差。由于 rsync 耗费算力过多,权衡成本后只能妥协在分钟级的滞后性上。
- 运维负担。多了个旁门左道的常驻进程,还得时常注意 rsync 的 CPU 占用率。
需要有更高生产力的日志系统才撑的住。
某日偶然和杨百万吹水,聊到日志传输的的问题。总结一下思路,每台机器上部署一个 "logging agent", 业务进程只需把日志投递到本机上的 agent,避开跨网传输的风险。投递完成的日志由 agent 转运并保证必达(Reliable Message Delivery)。
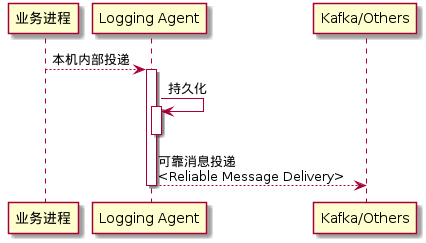
一切豁然开朗,有了实时可靠的日志投递,剩下的事就简单了。
- 审计日志实时导入 OLAP 系统。
- 程序日志实时导入 ElasticSearch ,以取代 grep 。
大事可期矣!
后记
这篇水文整理自我个人笔记里一些七零八落的碎片,聊作参考,避免重复挖坑。 相信不止我一人有类似的经历,也肯定有人一开始就站在了我想要到达的地方。不过这都不重要了,我们应该着眼于当下,积极接纳更先进生产力。
